Incident Response Plan and JSA Workflow for Field Service Companies

Field service owners tend to tell remarkably similar stories. The dispatch system goes down at 7 a.m. on the hottest day of the season. An OSHA inspector arrives and discovers that the safety binder is two months out of date. A tech was injured on Tuesday, only for the company to learn that the Job Safety Analysis (JSA) for the task was never completed. In each case, the problem begins as an operational oversight and eventually shows up as a cost on the profit-and-loss statement.
In owner discussions on Quora, the most commonly reported safety challenge in trade-service businesses is not the absence of a policy. The problem is that JSAs - the foundation of pre-task risk management - are often created on paper, modified informally as new employees are hired, and implemented inconsistently across crews and job sites. That gap is exactly what a formal incident response plan and documentation process is designed to close.
A pattern across multi-trade contractors we've worked with
Over the past two years, in mid-sized multi-trade contractors in Texas with crews subject to OSHA regulations, we have witnessed the same audit failures repeat. Shops manage JSAs, toolbox talks, and certifications on paper or across scattered drives that are organized well enough for foremen to use on a regular basis, but not well enough to produce within the 48 hours an OSHA Area Office may allow.
The anchoring case: A Texas multi-trade contractor was hit with an inspection in which the inspector requested 18 months of safety training records. The records were fragmented across binders, an old laptop, and the trucks used by foremen. The training had actually taken place. The evidence of it had not been properly maintained. The fine amounted to several thousand dollars, well within what a single citation can cost a 20-40 tech operation once indirect costs are included.
Leadership shifted records into a centrally managed electronic system where completion dates, signatures, and certifications were logged by tech. Subsequent audits went smoothly. One detail worth noting is that crews initially resisted the new sign-off process, and office staff spent several weeks backfilling historical data before the system became suitable for use as a permanent record.
This story is a composite based on the most common implementation patterns we have observed across operators in this vertical.
What an incident response plan actually does
The Incident Response Program (IRP) determines who makes the call, who is contacted, who is responsible, and who will work on the solution when something goes wrong and disrupts business operations. It helps eliminate the ambiguity between “something is not right” and “someone has taken the appropriate action to fix it.”
For field service shops, the scope extends beyond IT security. An operational IRP includes four types of disruption: cybersecurity incidents, operational outages, safety-related incidents, and regulatory exposure such as misclassification audits and OSHA citations. The plan addresses four questions before an actual incident forces an answer: Who is in charge, what constitutes a serious incident, How quickly do we need to respond, and what will we tell the client.
Three pillars hold up every working plan
Every IRP that can survive contact with a real-world incident is built on three load-bearing components:
- A clear incident-classification system based on severity and business impact, not technical complexity.
- Assigned owners with named backups, not just job titles.
- A defined response lifecycle that reduces downtime and creates a defensible record.
Categorize incidents before you rank severity
Not every incident is an emergency. If every issue is treated as one, the team responsible for responding will quickly become overwhelmed. Classification distinguishes routine issues from incidents that can cause lasting business harm.
Why categorization matters before severity does
Categorization helps a 5-20 shop determine, in simple terms, who responds, how quickly they must respond, and what level of authority is required:
- Prioritizes response efforts based on revenue impact.
- Identifies the right person, not just the most available person.
- Reduces confusion for leadership when multiple incidents occur simultaneously.
- Prevents the over-escalation of minor issues.
- Helps ensure the team remains productive despite interruptions.
Three incident types every field-service shop faces
Cybersecurity incidents. These threaten customer data, payment processing, and your ability to dispatch. The 2024 IBM Cost of a Data Breach Report puts the global average breach cost at $4.88M, and Microsoft's SMB research pegs the average 25-to-299-employee cyberattack at $254,445. Shops that recover quickly pre-stage manual dispatch procedures.
Operational disruptions. Dispatching outages, vehicle breakdowns, vendor failures, and payment-processing downtime do not attract media attention, but they can have a significant impact on revenue.
Safety incidents and OSHA exposure. The most under-built category in field-service IRPs. The 2024 BLS data shows plumbing, heating, and air-conditioning contractors at 3.0 nonfatal cases per 100 FTEs, electrical contractors at 1.8. Shops that handle these well treat the JSA as the front edge of the IRP, not a separate ritual.
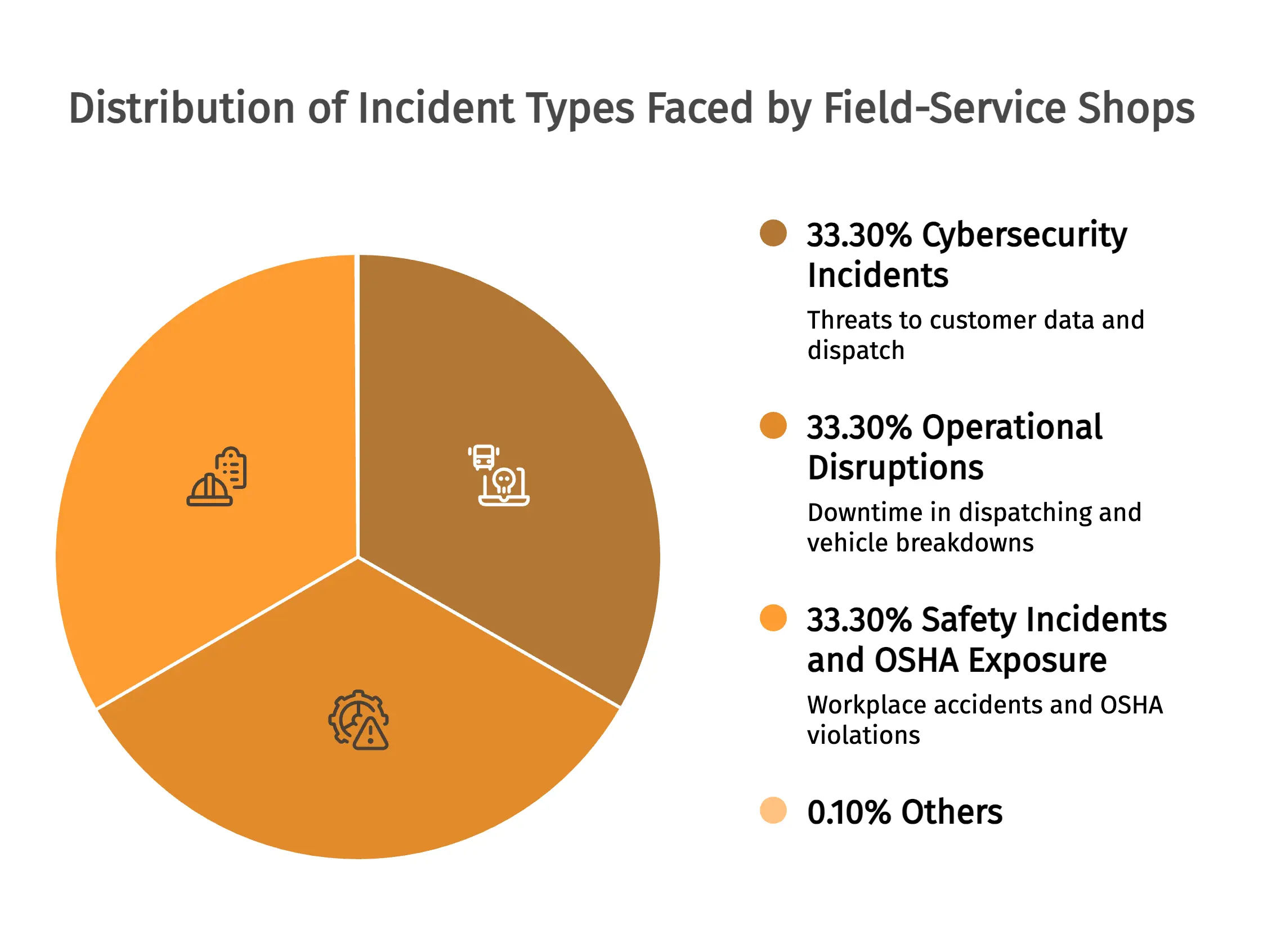
Severity levels that match business impact, not technical complexity
Level 1 (Critical). Customer safety, revenue, or legal compliance is immediately at risk. Examples include a complete dispatch outage during a heatwave, an active data breach, or a payment system failure. Response: immediate action, owner involvement, full team activation, and customer notification within minutes.
Level 2 (High). Operations are significantly affected, but workarounds may exist. Examples include a partial dispatch outage, regional scheduling failures, payment-processing issues affecting a portion of customers, or a near-miss safety event requiring investigation. Response: active oversight by senior operations staff and customer communication within 24 hours.
Level 3 (Moderate). The issue is disruptive but isolated. For example, a single technician is locked out of the mobile application because of a minor system glitch. Response: standard ticket-handling procedures and monitoring until resolution.
Level 4 (Low). The issue does not require immediate action and can be reviewed during the next scheduled maintenance window.
Roles named before the incident, not during it
When an actual incident occurs, confusion costs money. The plan should identify responsible individuals and their named backups. Job titles alone are not enough.
Why ownership wins under pressure
Without a predefined ownership structure, teams stall. Approvals are delayed. Multiple leaders provide conflicting instructions, and technicians caught between competing phone calls are left waiting while billable hours are lost. Clear role assignments enable the team to act faster than any technology solution alone.
The core incident response team
Five roles cover the vast majority of IRP responsibilities in a 5-20 shop. Each role should have both a primary owner and a designated backup.
Incident Commander. Owns the response process, declares severity levels, activates the plan, makes go/no-go decisions, and approves external communication. This role is typically handled by the owner or head of operations.
Operations Lead. Manages dispatch and technician load through the disruption. Works with the scheduling and dispatch software to keep work moving.
Technical Lead. Stabilizes systems. Coordinates with vendors or the QuickBooks integration layer or whichever piece broke.
Customer Communication Lead. Drafts updates, ensures consistent messaging across phone, text, and email, and prevents misinformation.
Legal or Compliance Advisor. Evaluates regulatory reporting requirements. OSHA’s 8-hour fatality reporting rule and 24-hour amputation or hospitalization reporting window are non-negotiable.
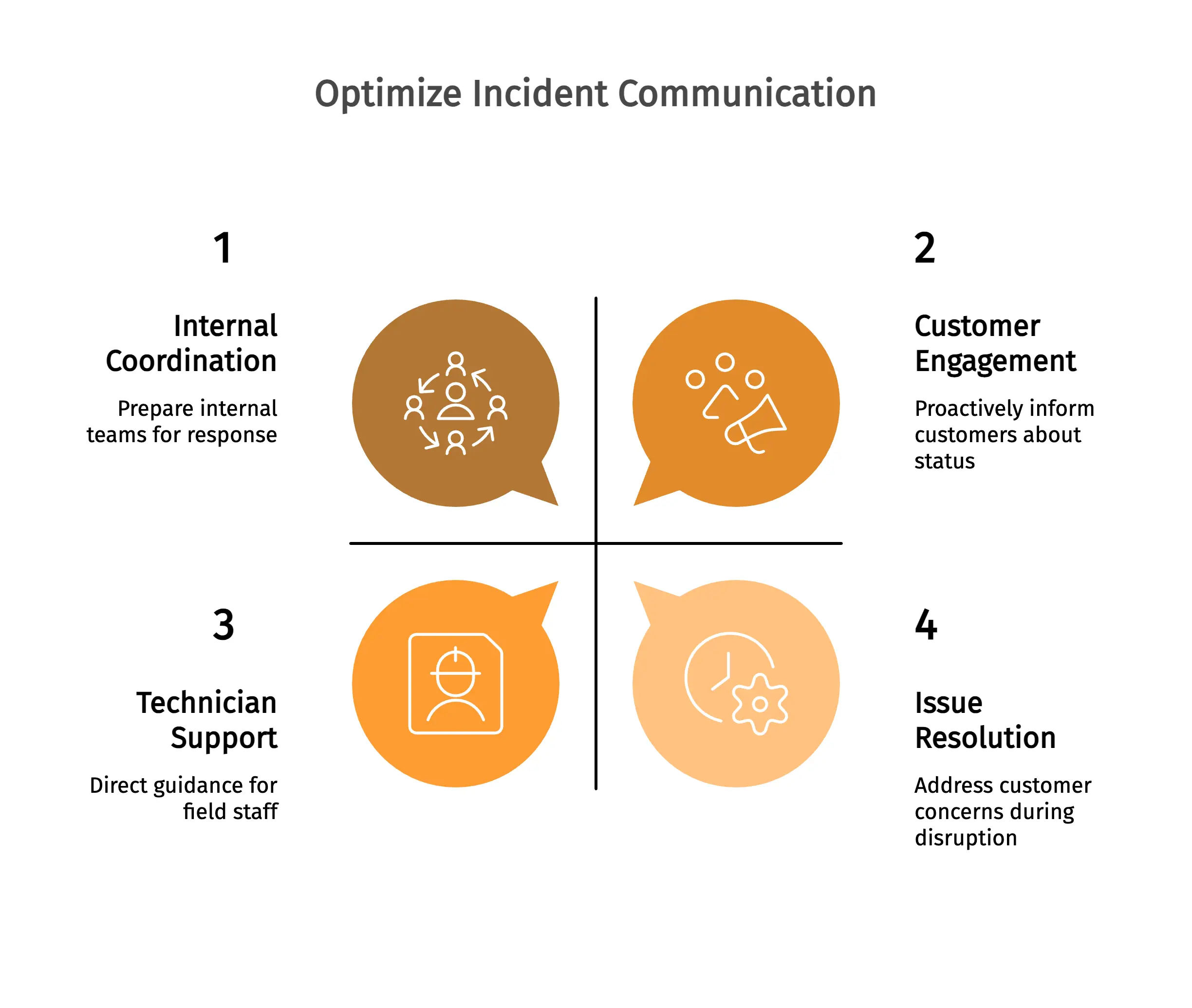
The communication plan, because silence is what customers won't forgive
Customers are willing to forgive technical issues. They do not forgive being ignored. Three communication tracks require predefined channels and prepared scripts before they are needed.
Internal channels
Pick one channel and stick to it: a dedicated Slack channel, WhatsApp group, or a real-time notifications thread. Fragmented conversations are how the same decision gets made twice and the wrong one sticks.
Talking to technicians
Technicians are the direct customer interface during any disruption. Provide them with clear instructions, regular updates every 30-60 minutes, and a clear on-site communication script. Mobile-app adoption directly affects how quickly technicians respond to an incident. If they regularly use the app during a normal workday, they are more likely to see critical messages within minutes.
Talking to customers
Customers need answers to three key questions: what happened, how it affects them, and when the issue will be resolved. Prepare templates for the most common disruptions, such as dispatch system outages, payment processing slowdowns, and safety incidents that affect scheduling. Speed and clarity are more important than polish.
The 6-function lifecycle, NIST CSF 2.0 aligned
The old four-phase model has been replaced. NIST SP 800-61 Revision 3, finalized April 2025, anchors response to the six CSF 2.0 functions: Govern, Identify, Protect, Detect, Respond, Recover. For a field-service shop, Govern and Identify get explicit ownership instead of being absorbed into "Preparation."
Phase 1: Preparation, the cheapest phase to do well
Build a System Map: every piece of software, the vendor support contact (not the generic inbox), the data it holds, and what breaks if it goes offline. Decide now what counts as Severity 1 and which vendors get a phone call vs. a ticket. Document the JSA workflow for each work type. OSHA's JSA guidance, codified in OSHA 3071, is what an inspector expects as your hazard assessment record under 29 CFR 1910.132(d).
Phase 2: Detection and analysis
Detection does not only refer to IT alerts. It can also involve a dispatcher noticing that three technicians called in because they were unable to log in within five minutes of each other. Record the start time, identify the first reporter, and note the affected systems. Examine the operational impact: how many jobs are affected, how much revenue is at risk, and how many technicians are blocked.
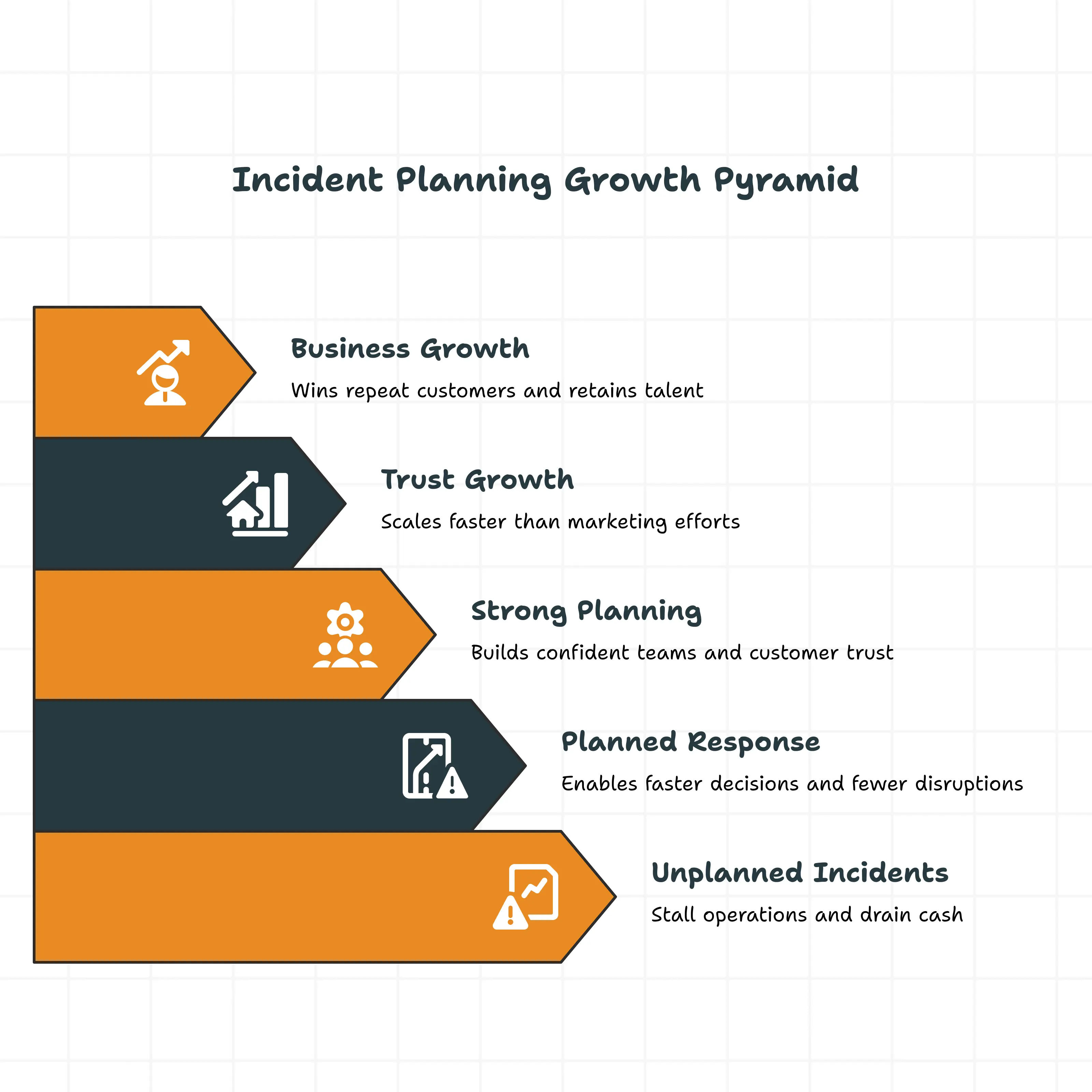
Phase 3 and 4: Containment and eradication
Stop the bleeding first, then address the root cause second. Containment is a business decision. It may involve turning off an integration, blocking a user account, or switching to manual dispatching. Someone should be authorized to make that call immediately without the need for a meeting.
Eradication is the cleanup phase. Remove the malware, shut off the access path, and fix the configuration error. Ensure the root cause is fully eliminated before restoring services. A second incident within one week will destroy your team’s confidence in the strategy.
Phase 5: Recovery, phased not flipped
Do not restore everything at once. Start by restoring core functions first, such as technician access, dispatch, and customer scheduling, followed by invoicing and payments, and then additional tools. Each layer should be monitored for 30-60 minutes before moving to the next. Inform customers about what was affected. Transparency during the recovery process is the second-largest trust signal, after the speed of the initial response.
Phase 6: Post-incident review and the lessons that don't evaporate
Schedule a one-hour review meeting within 72 hours. Review what went wrong, what worked well, and the overall costs involved, including overtime, revenue loss, churn risk, and exposure to regulatory risk. This creates the business case for the next phase of IRP investment. Then update the plan by adding a new severity threshold, an updated vendor escalation contact, and any missing JSA steps that should have been included earlier.
The field continuity playbook for when systems go down
If the digital side fails, the physical side must keep moving. A continuity playbook helps keep revenue flowing until the repair is made.
For dispatchers: a printed phone list of technicians, along with a paper job board that is updated every night in advance. A priority rule (emergency commercial first, followed by residential no-cool/no-heat calls, then routine jobs). A backup phone tree to handle vendor escalations.
For techs: the mobile app should work offline well enough to capture notes, signatures, photos, and time without connectivity. A paper job form sits as second-level backup.
For customer service: Prepared scripts such as, “We’re experiencing a system failure, but your technician is still scheduled to arrive at the original appointment time.” Confidence in communication helps customers stay calm.
JSA, OSHA documentation, and the $43,000 question
The National Safety Council pegs the average cost of a medically consulted work injury at roughly $43,000 in 2023. From 14 years of customer conversations, owners consistently tell us a single recordable in a 20-40 tech operation can wipe out a quarter of annual safety-program budget once indirect costs stack at the typical 3-5x multiplier.
OSHA doesn't require a document titled JSA, but 29 CFR 1910.132(d) requires written certification of hazard assessment, and the JSA method in OSHA 3071 is the technique inspectors expect. Fall protection (1926.501) has been OSHA's top citation for 14 consecutive years, and the current OSHA penalty schedule sits at $16,550 per serious violation and $165,514 per willful or repeated violation after January 15, 2024.
The operational pain owners explain: JSAs on paper require workers, supervisors, and safety leaders to walk through each stage of the job, and then repeat the process again with each new employee. In a typical tech shop with 5-20 tech operating with paper-based JSAs, owners estimate that only about 60% of pre-task forms are fully completed and legible by the end of the week. Shops that switch to a digital JSA module with required fields and missed-form alerts can boost completion rates up to 95%, because technicians are unable to close a work order without completing the required forms. In a business with 8 technicians, compliance paperwork time per tech decreases from around 5 hours per week to just under an hour.
.webp?updatedAt=1747733769120)
Here's what I see when a trade shop calls us after an OSHA citation. The training happened. The toolbox talks happened. The JSAs were walked. The proof of all of it was on three foremen's phones, in a binder in the office, and on a spreadsheet someone updated until July. When the inspector asked for 18 months of records, the operator had two days to assemble what should have been one search.
From 15 years of customer conversations, the pattern is consistent: shops don't fail audits because they're unsafe, they fail because they can't prove what they did. The other piece I'd push back on: I keep hearing the IRP is an IT document. For a 10-tech HVAC shop, the IRP is mostly a safety document with a cybersecurity chapter, not the reverse. The dollar exposure on safety is bigger, and the regulatory clock is faster.
- Joy Gomez, Founder of Field Promax
Retention compounds over time. Skilled trades experience a 73% annual technician turnover rate, according to 2026 Bridgit benchmarks, whereas mechanical contractors with formal safety-first training programs report approximately 20% lower turnover. Shops that consistently document toolbox talks, JSAs, and ongoing training are often the same businesses where senior technicians stay for more than three years.
An enterprise customer reviewing Field Promax on the QuickBooks App Store described deploying it across four businesses, citing customer service and customizations other niche tools couldn't match. The team management and compliance workflows that hold up under audit are the same ones that scale.
Worker classification: what AB 5 and AB 2257 change
Shops operating in California or hiring 1099 techs across multiple states need classification answered before an incident, not during. AB 5 codified the ABC test: the worker is free from control, performs work outside the usual course of the hiring entity's business, and is customarily engaged in an independently established trade. Prong B is usually the breaking point. If your techs do the core service you sell, they're employees in California by default.
AB 2257 added the B2B exemption but excluded construction services other than minor home repair. The willful-misclassification penalty under California Labor Code §226.8 runs $5,000 to $25,000 per violation, on top of unpaid wages, UI, and tax liability. The IRP should name who reviews classification quarterly and what happens when a 1099 tech is reassigned to work that crosses the ABC line.
Maintain the plan or watch it rot
The IRP should be reviewed every year, after every major incident, whenever you upgrade your software, or when you add a new service vertical or appoint a new operations leader. Conduct a tabletop exercise at least once a year: choose a Severity 1 scenario, walk your team through it for 60 minutes, identify any gaps, and then implement the necessary improvements.
Be the calm operator
The issue is not whether dispatch fails or OSHA arrives for an inspection. The real question is whether your shop has the right documentation, clearly assigned owners, and practiced response procedures to handle either situation without losing a quarter’s worth of revenue. The template below outlines the JSA checklist, severity matrix, roles and responsibilities, communication scripts, and post-incident reporting structure.
Related compliance playbooks
Continue with:
- Field Safety, Compliance, and Data Protection for Trade Shops
- Field Service Compliance Documentation: The JSA, Safety, and Audit-Trail Playbook
- Automated Field Risk Assessments and SOP Checks
- California Assembly Bill 2257: A Field Service Owner's Guide to AB 5 Classification
- Field Service Injury Prevention: 7 Accident Patterns and the Documentation That Defends the Shop
Frequently Asked Questions

Founder and CEO
Joy Gomez is an engineer, process automation expert, and the Founder of Field Promax. Known for his technical expertise and commitment to field service innovation, Joy writes about transforming traditional business models into paperless, efficient operations. He is a Lean Six Sigma Black Belt based in Rochester, MN, dedicated to helping field professionals work smarter through better technology.
Reviewed by

Content Creator
Bhargavi Halthore is a content writer at Field Promax, a field service management platform serving trades businesses across the USA and Canada. With over a decade of experience writing for business owners, she brings detailed, ground-level insight to every topic she covers. Her research goes beyond search results - she digs into LinkedIn groups, Facebook communities, and Reddit forums to understand what field service business owners are actually dealing with on the ground. She speaks directly with industry professionals, understands their day-to-day challenges, and translates that into content that is practical and actionable. What you read in her articles reflects real industry patterns, not theory.